



科技日报记者 陈曦 通信员 高雨桐
近期,OpenAI发布新一代人工智能模子GPT-5,再次激发全世界存眷。记者8月13日从南开年夜学获悉,该校计较机学院媒体计较试验室取患上最新研究结果,不仅从评估的角度展现了现有AI检测要领的机能不足,并立异性地提出了“直接差异进修”优化计谋,教会AI用“火眼金睛”鉴别人机差别,实现AI检测机能的巨年夜冲破。相干结果论文已经被ACM MM 2025(ACM多媒体国际集会)吸收。
跟着DeepSeek、ChatGPT、通义千问、豆包等天生式人工智能年夜模子逐渐从“新颖玩具”酿成进修、事情中不成或者缺的“出产力东西”,其伴生问题也日趋凸显:AI常常会“一本正经地乱说八道”,天生看似合理的虚伪信息,造成“AI幻觉”;依靠AI东西代写功课甚至卒业论文,极年夜打击着学术诚信及规范;论文AI率检测体系有待完美,论文被误判的问题时有发生……怎样精准辨认AI天生内容,成为亟待解决的热门问题。
今朝AI天生内容检测重要有两种线路,一种是“基在练习的检测要领”,利用特定命据练习一个专用的分类模子;另外一种是“零样本检测要领”,直接利用一个预练习的语言模子并设计某种分类尺度举行分类。
多项研究注解,现有检测要领于应答繁杂的实际场景时常显不足。此前也曾经有权势巨子媒体报导,《荷塘月色》《流离地球》等经典作品被某经常使用论文AI率检测体系检出高AI率。
为什么现有的AI检测东西会“误判”?论文第一作者、南开年夜学计较机学院计较机科学卓着班2023级本科生付嘉晨注释道:“假如把AI文本检测比作一场测验,检测器的练习数据等同在一样平常训练题,现有检测要领是机械刷题、死记硬违答题的固定套路,难以学会答题逻辑,一旦碰到全新难题,正确率就会显著降落。”
“要想实现通用检测,理论上需网络所有年夜模子的数据举行练习,但于年夜模子迭代飞速的今天险些不成能。”付嘉晨说,让检测器真正学会触类旁通,即晋升检测器的泛化机能,是晋升AI文本检测机能的要害。
为此,研究团队提出了直接差异进修(DDL)要领另辟蹊径,经由过程直接优化模子猜测的文本前提几率差异与报酬设定的方针值之间的差距,帮忙模子进修AI文本检测的内涵常识,可以精准捕获人机文本间的深层语义差异,从而年夜幅晋升检测器的泛化能力与鲁棒性。
“利用DDL练习获得的检测器犹如有了‘火眼金睛’,即便只‘进修’过DeepSeek-R1的文本,也能精准辨认像GPT-5如许最新年夜模子天生的内容。”付嘉晨说。
团队还有提出了一个周全的测试基准数据集MIRAGE,利用13种主流的商用年夜模子(如豆包、DeepSeek、Kimi等)以和4种进步前辈的开源年夜模子(如Qwen等),从AI天生、修饰、重写3个角度组织了靠近10万条人类-AI文本对于。
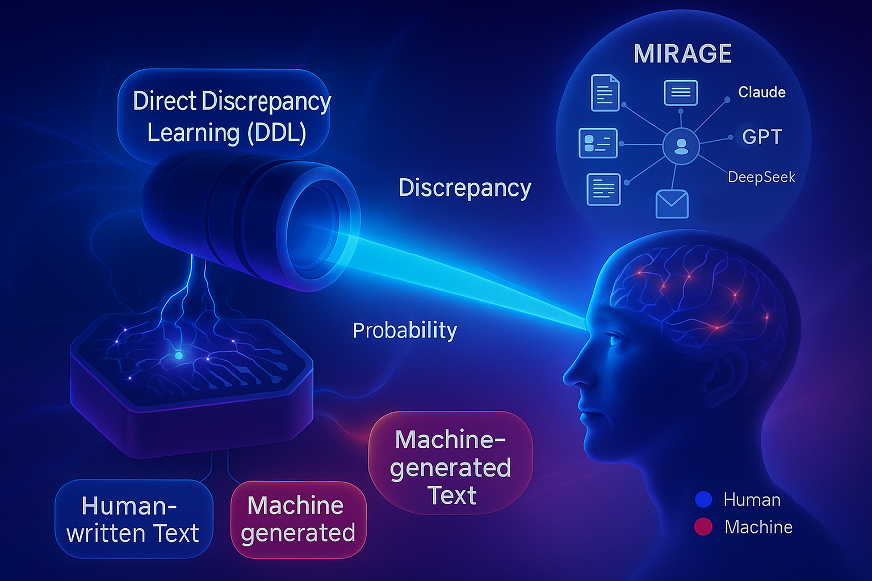
“MIRAGE是今朝独一聚焦在对于商用年夜语言模子检测的基准数据集。直不雅地说,以前的基准数据集是由少并且能力简朴的年夜模子命题出卷,而MIRAGE是17个能力强盛的年夜模子结合命题,形成一套高难度、又有代表性的检测试卷。”论文通信作者、南开年夜学计较机学院副传授郭春乐说。
于MIRAGE的测试成果显示,现有检测器的正确率从于简朴数据集上的90%骤降至约60%;而利用DDL练习的检测器仍连结85%以上的正确率。与斯坦福年夜学提出的DetectGPT比拟,机能相对于晋升71.62%;与马里兰年夜学、卡内基梅隆年夜学等配合提出的Binoculars要领比拟,机能相对于晋升68.03%。
“AIGC成长日月牙异,咱们将连续迭代进级评估基准及技能,致力在实现更快、更准、更低成本的AI天生文本检测,以AI之力,让每一一篇结果更出彩。”研究团队卖力人、南开年夜学计较机学院传授李重仪说。
-亿电竞
